コンピュータの言語理解
寺岡丈博准教授
自然言語処理とは
現在の研究
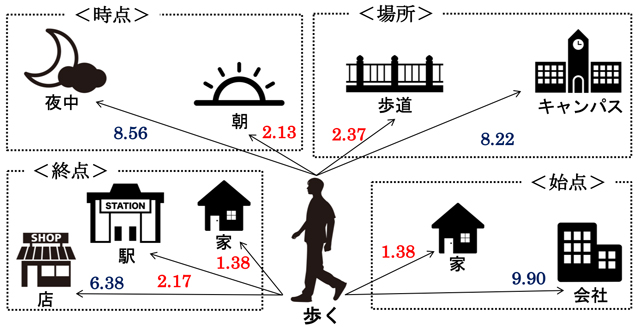
コンピュータは、人間が手に負えない程の膨大なデータを瞬時に処理できる一方で、私たちが扱う言葉の意味を正確に捉えるには色々な課題があります。例えば、私たちが普段何気なく使用している日本語(特に会話)には、主語や目的語の省略が往々にして見られます。コンピュータにとって「どこに何が省略されているか」を文脈に沿って正確に理解するのは、決して容易なことではありません。また、比喩や慣用句、擬人法などのレトリックが含まれることも理由の一つとして挙げられます。字義通り(文字通り)の解釈と、これらの表現を考慮した本来の解釈とでは意味が全く異なるからです。 本研究室では、大規模な実験データ(約3,200人分)から得られた人間の言葉に関する連想情報(図)をはじめコーパスやシソーラスから抽出した知識と機械学習を用いて、比喩解析や照応・省略解析、文生成など言語理解・生成の研究や、連想情報を利用した言語教育支援の研究に取り組んでいます。